Wrestling with the Python: Why AI Needs Digital Humanities to Make Sense of the World
-
Check out my GitHub repository Tools-to-Wrestle-with-the-Python for methods, tools, and datasets at the intersection of Digital Humanities and AI R&D, compiled during Oxford's Digital Humanities Summer School 2025 (St. Anne's College, University of Oxford. August 4-8, 2025)

In Frederic Leighton’s An Athlete Wrestling with a Python (1877), the figure of an athlete wrestles with a massive snake, locked in a struggle of endurance, strength, and meaning. The sculpture’s symbolism resonates today in a way Leighton could never have foreseen: the python is not only the mythical serpent but also the programming language that underpins most modern artificial intelligence.
This dual image captures the central paradox of AI development. On one hand, Python—the language of machine learning, deep learning, and natural language processing—empowers researchers and industry alike to extract unprecedented patterns from data. On the other, its algorithmic entanglement can constrict human interpretation, reducing meaning to statistical regularities while obscuring context, provenance, and lived realities.
The challenge is not to defeat this Python but to create the space for tension with it. Just as the athlete resists being overwhelmed by brute force, today’s innovators must develop interpretive techniques that counterbalance computational efficiency with cultural, ethical, and contextual insight. Not a struggle but a designed system of accountability: it is precisely through resistance and counterforce that AI systems can become tools for understanding rather than engines of distortion.
Photograph by Frederic Leighton, Public domain, via Wikimedia Commons
This article explores that tension through two lenses, shaped by my own reflections and learnings during Oxford's Digital Humanities Summer School 2025 at St. Anne’s College, Oxford University.
First, it reviews key critiques of language technologies that warn against the collapse of meaning into form, the reproduction of systemic biases, and the limits of contextual embeddings. Second, it turns to methods drawn from digital humanities, which are fields that have long grappled with meaning, representation, and data integrity, to show how interpretive infrastructures can guide AI toward more trustworthy, transparent, and resilient innovation.
By reframing the problem of AI not as a purely technical challenge but as an interpretive one, Digital Humanities points to new ways for industry and research to innovate responsibly. As Nicholas Cole, director of The Quill Project and one of the summer school’s speakers, put it bluntly: “we should not be satisfied with the technologies created by non-humanists”.
Too often, tools are built for speed, scale, and efficiency, while context, meaning, and responsibility get pushed aside. What Digital Humanities shows is that interpretation itself can be designed into our systems: through practices of annotation, provenance, and critical framing, so that AI doesn’t just compute but actually supports more accountable and human-centred decisions.
“We should not be satisfied with the technologies created by non-humanists ”
Lost in Translation: AI and the Limits of Understanding
Generative AI has leapt from research labs into everyday business. Large language models (LLMs) like the recently deployed GPT-5, Claude, Gemini, and many others now draft reports, answer customer queries, generate code, and even support decision-making. With the rise of agentic AI—systems that not only generate text but also act across tools, APIs, and workflows—the stakes are getting higher.
But here’s the paradox: technological sophistication is not the same as understanding. Data choices shape behaviour, decisions at every level are being made based on what a machine interpreted from a text, an image, a number. A system can sound confident and act autonomously, while still lacking access to meaning, intent, or grounded truth. That gap is where risk lives—whether it’s reputational damage, compliance failures, or very expensive, dangerous mistakes.
Researchers have been flagging this problem for years:
Bender & Koller (2020) argue that LLMs trained purely on linguistic form cannot access meaning or communicative intent. Pattern mimicry should not be mistaken for comprehension.
Smith (2019) explains how contextual embeddings capture token-in-context usage, enabling transfer and downstream improvements. Yet they remain grounded only in text, not in the external world.
Rogers (2021) shows that the single strongest lever for model reliability is data curation. Training sets that are biased, narrow, or poorly documented inevitably produce brittle systems. Since datasets already shape behaviour, their governance must be explicit.
Together, these insights expose the interpretation paradox: as LLMs and agentic AI become more convincing, the need for human interpretation, oversight, and grounding actually increases. Businesses should resist the temptation to equate certainty and accuracy KPIs with understanding.
Four Critical Insights for GenAI and Agentic AI
Meaning vs. Form: LLMs predict the next most likely word; they do not “understand.” For agentic AI, this is crucial: if the agent is driving workflows or executing code, misinterpreting form as meaning can create cascading errors.
Context Without Grounding: Contextual embeddings (Smith, 2019) model polysemy and syntax, but remain tethered to text. Agentic AI amplifies this issue: when systems act on external APIs or enterprise data, text-only grounding increases the risk of confident but wrong actions.
Data as the Behaviour Dial: As Rogers (2021) notes, models inherit the worldviews of their datasets. For agentic AI, this is magnified: an autonomous agent’s behaviour is only as safe and robust as the data it was trained or fine-tuned on. Poor curation is not just a technical flaw—it’s a liability.
The Interpretation Paradox: The more fluent and action-capable these systems become, the more they invite misplaced trust. For businesses deploying agentic AI, this paradox translates into a governance imperative: build safeguards that limit what the system is trusted to decide or do on its own.
What This Means for Data-Driven Innovation
Adopt a data-product mindset: Treat datasets and fine-tuning corpora as first-class products. Track provenance, demographic coverage, consent, and versioning. Run periodic audits and red-teaming. For agentic AI, extend this principle to the tools and APIs an agent can access—document them, monitor them, and govern their use.
Use LLMs and agents responsibly: Leverage GenAI for summarisation, classification, or ideation, but represent outputs as predictions, not facts. For agentic AI, add grounding layers: constrain actions to vetted APIs, integrate structured knowledge, and require human review for high-stakes tasks.
Evaluate beyond benchmarks: Leaderboards don’t reveal system fragility. Businesses should adopt stress testing, subgroup robustness checks, and out-of-distribution evaluations. For agentic AI, simulate workflows end-to-end, monitoring for hallucinations, cascading failures, or unsafe behaviours.
Institutionalise interpretive oversight: Stand up interdisciplinary oversight boards—including domain experts, ethicists, and affected users—for both datasets and agentic workflows. Tie product claims directly to what Bender & Koller (2020) call the boundary of machine “understanding.”
What Can AI-Driven Innovation Learn from the Humanities to Make Sense of the World?
One of the most powerful insights from the Oxford Humanities Data Programme is that digital humanities has long grappled with the same questions now pressing AI and data-driven research and innovation: How do we ensure that data retains meaning? How do we capture context, provenance, and interpretation, rather than reducing data to form alone?
The following recommendations, grounded in the programme’s sessions, show how established digital humanities practices can inform innovation and R&D teams in building more robust, transparent, and meaningful data systems.
In this section I tried to summarise the key ideas, tools and methodological approaches surfaced in the programme, organised as recommendations for research and development teams.
1. Critical Evaluation of Data Standards
Neil Jefferies, from The Bodleian Libraries, University of Oxford, explained how just as scholars interrogate sources, data practitioners must question standards and structures rather than adopting them uncritically. Part of his presentation has been summarised here.
When you work with data, whether in research or in product development, the standards and tools you rely on will determine how far your work can travel and how long it remains useful. The temptation is often to treat technologies as neutral, but in reality they carry the assumptions, incentives, and blind spots of the communities that built them. This is why critical evaluation matters as much as technical implementation.
“The wonderful thing about standards is that there are so many of them”
What to Watch For
Not every standard is worth your time. If there's no active community using it, it won't survive. If two different implementations can't actually work together, calling it a "standard" is just marketing. Sometimes people chase novelty for its own sake, publishing new frameworks that barely improve on what already exists.
Think long-term. Your work needs to be persistent, discoverable, understandable, citable, and versioned, or it'll disappear into digital obscurity. A random file dumped online doesn't cut it.
Layers of Knowledge: Information isn't flat, it has depth. Take text as an example. At the bottom layer, you have physical properties: file size, format, where it lives. Then structural elements like headings and paragraphs. Above that, linguistic features—language, dialect, grammar. Context adds historical references and proper nouns. Interpretation brings in annotations and connections to other works. Metadata weaves through everything, tracking who made what and how certain we are about it. Which layers matter depends entirely on what you're trying to accomplish.
Clarifying Aims: Before picking any format or tool, ask yourself: what question am I actually trying to answer? Not all information carries equal weight. Who's your audience? What are you really putting out there? Cast a wider net and you're more likely to get cited and reused. Timing matters too. Do you need to publish fast, or are you building something for the long haul? Retrofitting data later is painful and expensive. If jamming your information into a standard feels forced, you're probably using the wrong approach.
Good Habits: Find communities that share your goals and build on what they've already figured out. Fight the urge to reinvent the wheel. Search the literature for existing standards and adapt them instead. Take the long view. Recognition for reusable data takes time, but impact increasingly gets measured this way. Keep the FAIR principles in mind—Findable, Accessible, Interoperable, Reusable—but don't treat them like commandments. Machine access is becoming more important, but human interpretation still matters most.
Why This Matters for AI and Machine Learning
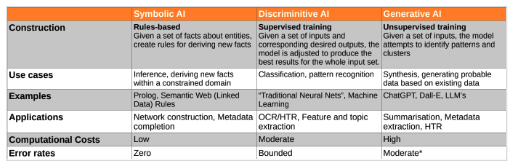
Most of today's AI runs on machine learning, where models learn from datasets and reflect whatever biases those datasets contain. In humanities research and many business contexts, large, well-curated datasets are scarce.
Commercial AI systems train on whatever they can scrape from the internet—which is neither unbiased nor reliable.
The result? Systems that sound confident while being completely opaque about their reasoning. Always double-check their outputs. When possible, use a second method to verify results. As digital tools get more sophisticated, machines might handle data processing without human help. But the outputs they generate will always need human judgment.
2. Corpus Management and FAIR Principles
Managing data well is the foundation of reliable AI, trusted insights, and long-term digital value. In linguistics, the way corpora (large, structured collections of texts) are designed, annotated, and shared provides lessons for any organisation working with complex, unstructured, or sensitive datasets.
Megan Bushnell and Martin Wynne, from CLARIN-UK, explained corpus linguistics and how to curate large-scale textual datasets for reuse, reproducibility, and interoperability. Their message is clear: good data management turns information into reusable knowledge, while poor practices lock value away or create risk.
Corpus linguistics is not about abandoning traditional methods. It is about expanding the research toolkit. Digital approaches should complement exploration, close analysis, interpretation, and understanding of texts, discourses, art, history, and society.
If traditional methods are neglected, the accessibility of digital data can make poor research more likely. The temptation is to skim across texts without the deep familiarity that serious interpretation requires. This risk is visible in the naive use of tools like Google Ngrams or simple word clouds. These visualisations can be attractive, but they often raise more questions than they answer and can easily mislead. Today, large language models present similar challenges. They generate outputs that feel authoritative yet conceal the processes that produced them, giving the illusion of easy answers.
What's the ultimate aim in Digital Humanities? Ways to combine close reading with big data approaches.
What is needed are tools that operate like different kinds of lenses. A macroscope reveals broad patterns and tendencies across large collections of texts, offering what Franco Moretti once called “distant reading.” A microscope brings the detail of close reading into focus, letting the researcher examine subtle textual or linguistic features. A zoom lens enables movement between the two, switching from wide perspective to fine detail.
This is what scalable reading requires: the ability to shift between levels of analysis, to see the big picture and the intricate detail, not simultaneously but with the agility to move between them.
Lessons from Corpus Linguistics for Context-Aware Innovation
Data is never neutral: Corpus linguistics reminds us that every dataset is shaped by choices, priorities, and trade-offs. Standards and tools embody the values of their creators. Asking “who benefits, who controls, and who decides?” is as important as asking “how accurate is this?”.
FAIR and CARE Principles as Dual Guides: FAIR makes your data useful; CARE makes it responsible. Together, they form a governance lens that innovation teams can adopt immediately.

3. Shared Infrastructure is a Force Multiplier: Europe’s CLARIN network shows what happens when data, tools, and expertise are aligned across borders. Researchers can log in once, access repositories, use analysis tools, and deposit improved data back into the ecosystem. For businesses, this model suggests the need for shared data hubs, trusted repositories, and community-driven standards, instead of siloed, one-off projects.
4. Treat Datasets as Products: In both research and industry, the demand is shifting and funders, partners, and regulators want proof that data is documented, curated, and sustainable. This means adopting practices like:
Persistent identifiers (DOI/HDL)
Data Management Plans (DMPs) as living documents
Depositing in certified repositories
Transparent licensing and attribution
How to Spot an un-FAIR Corpus
When working with text or language datasets, it is easy to assume they are “good enough” for analysis. But if a corpus is not FAIR (Findable, Accessible, Interoperable, Reusable), it risks being unusable, misleading, or even harmful for research and innovation. Use this quick guide to assess whether a corpus meets FAIR standards—or where it falls short.
Is it Findable? Without identifiers and metadata, your dataset is invisible to others, making collaboration or verification almost impossible.
Warning signs of an un-FAIR corpus:
No unique or persistent identifier (like a DOI or stable URL).
Sparse or vague metadata that does not describe content, scope, or source clearly.
Not listed in a trusted repository or registry, meaning it is hard for others to discover.
Is it Accessible? Data locked away or hidden behind unclear access rules cannot contribute to reproducible science or transparent development.
Warning signs:
The identifier points to a broken link or inaccessible location.
No clear system for authentication or authorization when access is restricted.
Metadata is hidden along with the data, instead of being openly available.
Is it Interoperable? If your corpus cannot “talk” to other datasets, it limits comparative research, automation, and innovation.
Warning signs:
Data stored in obscure or proprietary formats with no clear export options.
Metadata that does not follow community standards (e.g., no Dublin Core, OLAC, or CMDI).
Poor or missing documentation.
No cross-references to related resources, making integration with other datasets impossible.
Is it Reusable? Without context and licensing, other researchers cannot safely or legally reuse the resource, making your work a dead end.
Warning signs:
Lack of contextual information about how, why, and by whom the corpus was created.
No license or unclear licensing terms.
Hosted outside certified or sustainable repositories, with no way to cite the corpus reliably.
Create a Data Management Plan
A Data Management Plan (DMP) is more than a compliance document. It is a roadmap for how data will be handled during and after a project, ensuring it remains usable, accessible, and trustworthy over time. In practice, a DMP applies the FAIR data principles—findable, accessible, interoperable, reusable—and brings structure to what can otherwise be a chaotic process.
A strong DMP typically includes:
Type of data: what is being collected or generated.
Standards and metadata: how the data will be described and formatted for reuse.
Storage and security: where it will live, how it will be protected.
Sharing and access: who can use it, and under what conditions.
Responsibility and preservation: who is accountable, and how the data will remain available over the long term.
Why does this matter? In research, a DMP helps teams stay organised, reduces the risk of data loss, and makes it easier for others to reuse and build on results. Funding bodies like the European Commission and the US National Science Foundation (NSF) now require DMPs as part of proposals, underscoring their importance.
For industry, the case is just as strong. A DMP functions as a governance framework for data-driven innovation. It ensures clarity on data provenance, safeguards compliance with regulation, and builds trust with users and stakeholders. Instead of treating data curation as an afterthought, a DMP embeds it as a core capability—supporting transparency, auditability, and long-term value creation in product development.
3. Data Visualisation for Innovation and R&D
Data visualisation is not just about making data look good. It is about making data usable. In research and innovation, visual tools can expose trends, reveal gaps, and help teams move from raw information to meaningful insight. The value of visualisation is in giving people the ability to think more effectively with data. In other words, visualisation does not replace human judgment, it augments it.
Alexander Shiarella showcased visualisation functions not only as output but also as a method of discovery, surfacing hidden structures in complex datasets. This echoes the concern with interpretability, providing a bridge between opaque data patterns and human understanding.
“Data visualisation is the graphical representation of information and data. By using visual elements like charts, graphs and maps, data visualisation tools provide an accessible way to see and understand trends, outliers and patterns in data”
Why It Matters
For R&D teams working with AI, large language models, or experimental datasets, the risk of misinterpretation is high. A well-designed visualization can lower that risk by showing both the “big picture” and the hidden details. Poor visualization, on the other hand, can distort, oversimplify, or create false confidence.
Approaches to Visualisation
The field has evolved through three overlapping traditions:
Scientific visualisation, where graphics show physical or simulated phenomena.
Information visualisation, where abstract data (like text, networks, or time series) is mapped into visual form.
Data journalism and business intelligence, where charts and dashboards guide fast decisions.
Innovation teams often need all three. The challenge is to know which to use and when.
Good Practice for R&D
Treat visualization as part of analysis, not decoration.
Test different visual idioms for the same dataset. What works for one audience may mislead another.
Align tools with scale: lightweight platforms for quick exploration, advanced frameworks for production and integration.
Plan for reproducibility. A visualisation should be as citable as a dataset or algorithm.

“The essence of abstraction is preserving information that is relevant in a given context, and forgetting information that is irrelevant in that context”
V. Guttag, 2021
Giles Bergel explained how meaning often lies beyond text. Multimodal approaches integrate images, sound, and other cultural data types, expanding the interpretive scope of AI beyond language-only models.
4. Preservation and Provenance Tracking
Edith Halvarsson, Digital Preservation Specialist at Bodleian Libraries, presented her work on digital preservation to ensure that data remains interpretable across time; Neil Jefferies explained how provenance tracking maintains accountability for interpretive decisions. These topics mitigate the critique of “changing the world by changing the data” without transparency.
“Digital Preservation refers to the series of managed activities necessary to ensure continued access to digital materials for as long as necessary” - Digital Preservation Coalition. With this premise, it’s critical to get ahead of the pace of technological change in order to preserve digital information. This happens by anticipating and planning for maintenance/rebuilding, while choosing technologies and standards that put us in the best possible position to do so.
What happens when the original infrastructure were data was first captured ceases to exist? How is data being preserved considering all the varied technology lifespans?
Acid free paper takes up to 1000 years to degrade
Hardware becomes obsolete in between 3-5 years
Software is replaced every 6-8 years
An average company lifespan (S&P 500) is less than 20 years
Case Study: The BBC Domesday Project
In 1986, the BBC launched the Domesday Project to mark the 900th anniversary of William the Conqueror’s Domesday Book. It was a groundbreaking crowdsourced digital archive, gathering contributions from over a million people, schools, and communities across the UK. The data was stored on LaserDiscs, using proprietary hardware and software.
Within just a few years, the discs became unreadable because the technology was obsolete. What had been an ambitious attempt at building a national digital memory was at risk of total loss. It took decades of specialised recovery work to preserve the content, some of the approaches used were:
Emulation
Computer museum
Contextual documentation
Content extraction/Platform migration
Cutting-edge projects can quickly become inaccessible if built on fragile or proprietary formats. Long-term preservation requires open standards, careful documentation, and active planning for future access. Without this, even the most visionary digital initiatives can disappear into digital oblivion.
For more information on this topic, go to Digital Preservation Coalition.

By simon.inns - https://www.flickr.com/photos/130561631@N03/40268524461/, CC BY 2.0, https://commons.wikimedia.org/w/index.php?curid=110039701
On the topics of context and provenance, Jefferie’s session explored how digital objects derive meaning not just from their intrinsic data but from context and provenance. A file on its own is only a stream of bytes; the real intellectual content comes from metadata, relationships, and the history of how that object was created, curated, and transmitted.
Some key takeaways for an innovation process:
Knowledge vs Data: Knowledge is not fixed. It is time-bound, sometimes contradictory, and full of gaps. Effective models must reflect this complexity rather than force data into rigid structures.
Models for Organising Information:
Tables: Simple lists, efficient for limited relationships.
Trees: Useful for hierarchies and classifications but limited to one structure.
Graphs/Networks: Better for representing complex, multi-dimensional relationships (RDF, relational databases).
No One-Size-Fits-All: Different information types require different models. Forcing everything into one structure reduces reusability and efficiency.
Data vs Metadata: Metadata can carry more meaning than data itself. Provenance (the chain of custody) and context (original creation conditions) are essential for trust, reproducibility, and long-term preservation.
Evidence and Assertions: Knowledge models are assertions, not absolute truths. Understanding who made a claim, when, and on what evidence is crucial for evaluating reliability.
Preservation and Reuse: Choosing formats, capturing context, and documenting processes all influence whether data can be reused, preserved, or meaningfully integrated with other resources.
Linked Data and RDF: RDF triples (subject–predicate–object) enable linking across domains and contexts, but not everything belongs in RDF. Use it strategically where graph-like complexity is needed.
AI and Meaning: Symbolic AI can enrich datasets through rules and inference, while language-based AI can extract relationships from text. Both require careful handling of contradictions, uncertainty, and gaps.
Choosing the Right Model: Start with the Question
When working with data, the first step is not to pick a technology but to ask: what problem are we trying to solve?
The nature of your question should guide how you structure and represent information. If your data involves only a few kinds of objects and relationships, repeated at large scale, then a relational database may be the best fit. It provides efficiency and stability when patterns are simple but numerous.
If, however, your data involves many different kinds of objects and relationships, but relatively few instances of each, then graph-based approaches like RDF are more appropriate. They allow you to model the complexity of networks, connections, and provenance in a way that relational tables cannot.
For projects that are tabular or hierarchical in nature, with limited relationships, simpler formats may suffice. Sometimes, the overhead of complex data modelling is unnecessary. In these cases, clarity and focus matter more than sophistication.
And sometimes, the best choice is not to build a complex structure at all but simply to write the paper. Not every research or innovation problem needs to be captured in a database or a knowledge graph.
The message is simple: let the problem lead the method. Technology should serve the research question, not the other way around.
Qualifying Knowledge: Beyond the Assertion
Data is never just a set of facts. Every statement or record we work with is an assertion that must be qualified if it is to be useful, trustworthy, and reusable. To frame knowledge responsibly, we need to ask a series of questions about each assertion:
Time: When was this true? A person may exist in one century but not another, or hold a position during a limited period.
Place: Where is this true? An academic might be Professor of History at Oxford, but later at Heidelberg. Locations themselves shift over time, as political boundaries and jurisdictions change.
Source: Who made the assertion? An anonymous text is still a valid source, but its anonymity affects how we interpret it.
Evidence: Why was the assertion made? What data or reasoning supports it? Equally important, what counter-evidence exists?
Confidence: How much should we trust this assertion? Confidence depends on the credibility of the source and the quality of the evidence.
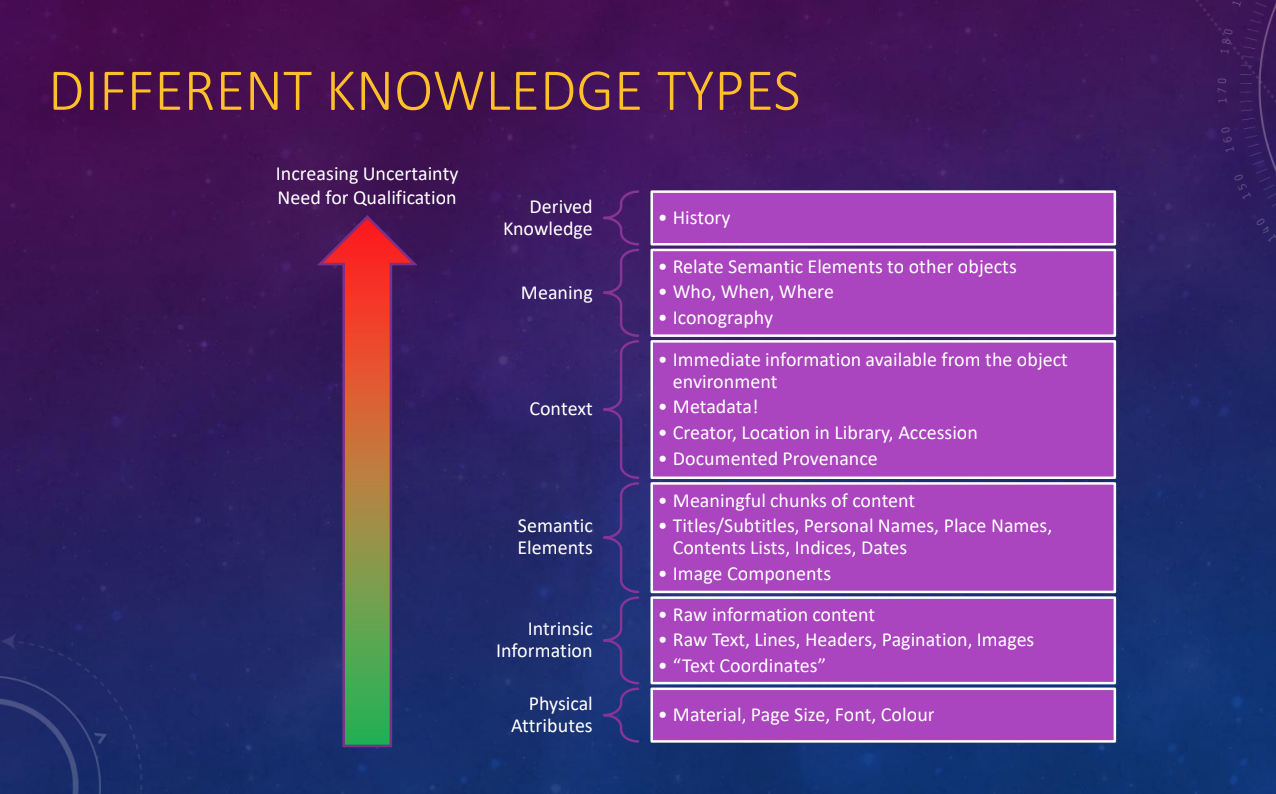
By Neil Jefferies
This framework highlights a core weakness of today’s AI systems, especially large language models. LLMs generate text with fluency and confidence but do not qualify their assertions. They rarely indicate when or where something is true, who made the claim, or why it should be trusted. For innovation and R&D teams, this creates risk: outputs that sound authoritative but lack grounding.
By adopting the practice of qualifying assertions with time, place, source, evidence, and confidence, we can design workflows, standards, and even AI systems that are more reliable and accountable. In other words, the humanities’ careful approach to knowledge framing is not an academic luxury—it is a practical safeguard for data-driven innovation.
Modelling Knowledge with Linked Data
When organisations talk about “data”, they often mean rows in a spreadsheet or entries in a database. But as data grows more complex, those formats struggle to capture relationships, history, and meaning. This is where Linked Data and the Semantic Web come in.
Tim Berners-Lee first proposed the Semantic Web in 1998 as a way of making the web not just a collection of documents, but a web of knowledge. At its core is the RDF triple—a simple structure that expresses a relationship between two things: subject, predicate, object. For example, “Marie Curie — worked at — Sorbonne.” A collection of triples forms a graph, which can then be queried and linked across datasets.
Key components of this ecosystem include:
URIs: unique identifiers for anything, from people to datasets.
Unicode: making the system multilingual from the start.
RDF (Resource Description Framework): the backbone for expressing data as triples.
OWL (Web Ontology Language): a way to define vocabularies and relationships so that triples remain interoperable.
SPARQL: a query language for searching across RDF graphs stored in “triple stores.”
JSON-LD: a newer format that integrates Linked Data easily into web applications.
Berners-Lee later added the idea of Linked Open Data (2006), a set of practical rules for publishing data that machines can understand and connect. He even proposed a “five-star” system: start by putting your data on the web, then make it machine-readable, open, structured, and—at the top level—linked to other people’s data to provide context.
What does this mean in practice? Instead of siloed datasets, we can build interoperable graphs where information about people, places, or events connects across sources. Projects like Wikidata and GeoNames are built on these principles, making them valuable backbones for innovation and R&D.
The Prov-O ontology, a W3C standard, adds another layer: provenance. It allows us to qualify assertions by recording who created a dataset, what roles were involved, and what activity it relates to. This is critical for trust. Without provenance, datasets risk becoming black boxes with unknown origins.
For organisations experimenting with AI, especially language models, this matters. LLMs are good at producing fluent answers, but they rarely qualify when, where, or why something is true. Linked Data modelling provides a counterbalance: a structured way to encode relationships, context, and provenance so that outputs are explainable and auditable.
It also shows a bridge between symbolic AI (rule-based reasoning over triples) and statistical AI (pattern recognition in text). Symbolic systems can enrich data and simplify workflows—for example, if “A is the son of B” and “B is the son of C,” the system can infer “A is the grandson of C.” Meanwhile, language-based AI can help extract triples from text. But combining them responsibly requires care: contradictions, uncertainty, and gaps in data can produce misleading results if not managed properly.
The lesson for innovation teams: do not treat Linked Data as an academic curiosity. It is a practical framework for managing complexity, qualifying knowledge, and ensuring data remains usable across time, systems, and contexts. Before storing data in silos, ask instead: How might this become part of a larger graph of knowledge that others can trust, use, and extend?
5. Data Cleaning and Relational ModelLing
Edith Halvarsson, Meriel Patrick, Pamela Stanworth and Sebastian Dows-Miller on how cleaning and structuring messy data reduces error propagation and enables richer queries. This practice supports Smith’s insight that embeddings rely on the quality and structure of their training data.
Why These Tools Matter for AI-Driven Innovation
AI systems, particularly large language models and machine learning pipelines, are only as strong as the data they are built on. Messy, inconsistent, or poorly structured data leads to unreliable results and compounds risk when decisions are automated. For R&D teams, the priority is not simply collecting data but preparing it in a way that is clean, structured, and interpretable over time.
This is where tools like OpenRefine, relational databases, and TEI encoding come in. They address three critical stages: cleaning raw data, structuring it into usable models, and encoding it with context so it can be reused across different systems. Together, they provide a workflow that transforms raw sources into high-quality datasets that AI systems can learn from and that humans can trust.
These following three approaches offer a scalable path from raw, messy sources to well-structured, interoperable data. This workflow ensures datasets are reliable, reusable, and ready for advanced applications in innovation and AI-driven R&D.
OpenRefine for Tabular Data: a free, open-source tool designed to work with messy tabular data. It runs in the browser and supports many formats such as CSV, Excel, JSON, and XML. Its main strengths are cleaning and standardising data, resolving typos or inconsistent formats, deduplicating records, and transforming datasets into more usable structures. It also supports reconciliation against external authorities such as Wikidata, VIAF, or Crossref, making it easier to enrich data with verified identifiers. OpenRefine records every step in a project history, which helps teams audit and reproduce workflows. For R&D teams, it is especially useful in preparing datasets for analysis where consistency and traceability matter.
Relational Databases: When projects involve multiple entities and relationships, relational databases provide a robust way to organize and query data. They structure information into tables with rows (records) and columns (fields), connected through primary keys and joins. Relational databases are especially valuable for R&D teams dealing with incomplete or complex data, where traceability and flexibility in querying are essential.
TEI to Encode and Extract Data: The Text Encoding Initiative (TEI) provides XML-based guidelines for marking up and encoding texts in a structured way. It allows researchers to capture not only the content but also metadata such as structure, annotations, and contextual information. With TEI, texts can be transformed into datasets that are queryable and interoperable with other standards.
For data modelling, TEI acts as both a preservation standard and a bridge to computational methods. By encoding texts at a granular level, it becomes possible to extract structured entities and relationships, making them ready for integration into databases or linked data frameworks.
The Workflow for Designing a Relational Database
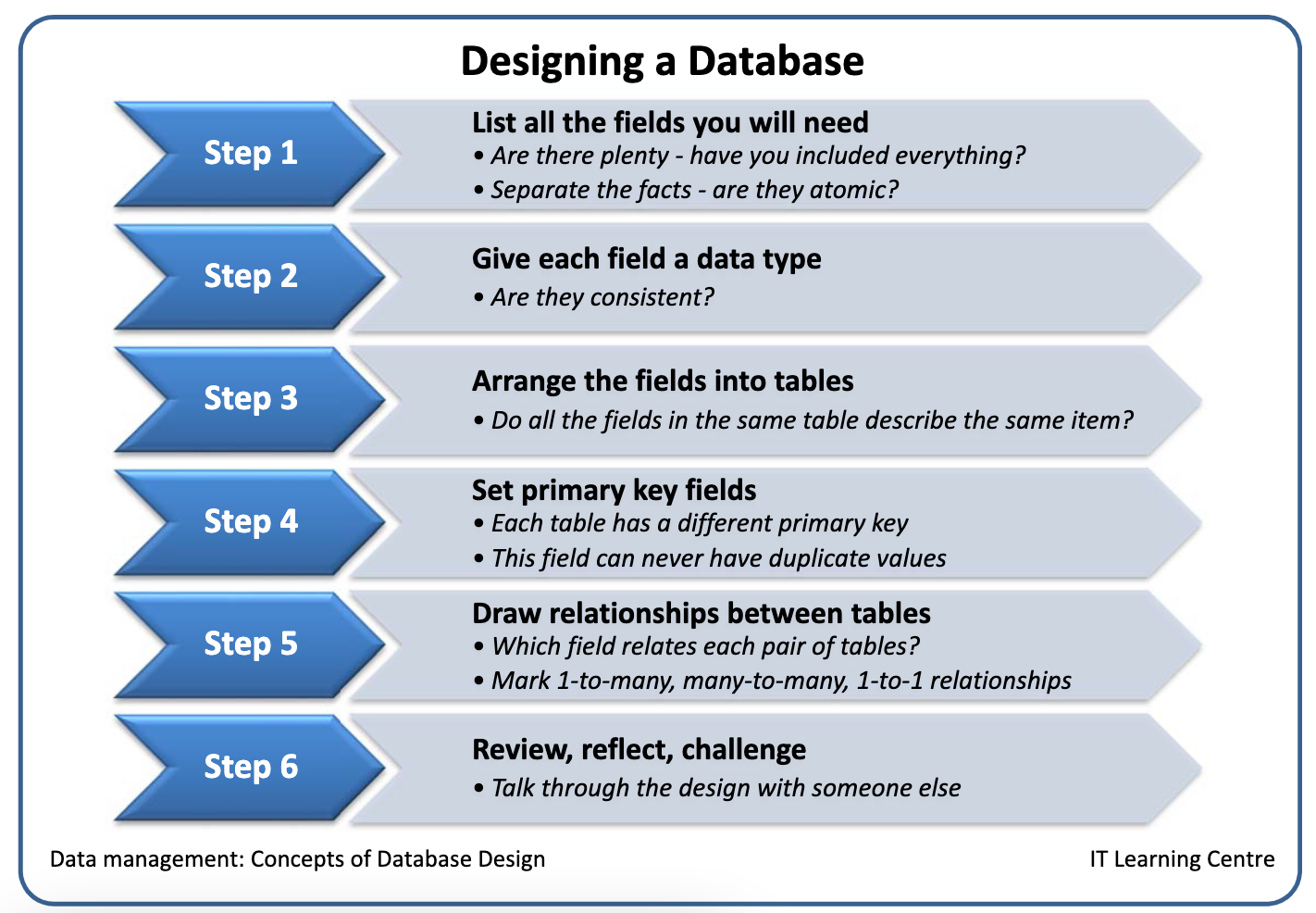
Designing a relational database is not just a technical exercise but a way of thinking through what knowledge you want to capture and how it connects.
A well-designed database can scale, adapt, and serve as a backbone for both research and AI applications.
Step-by-step of designing a database,
Define your purpose
What questions should the database help answer? This will shape what information is essential to capture.Identify entities
List the main “things” in your data. These might be people, events, places, organisations, or documents.Decide on attributes
For each entity, define what facts you want to record. For example, for people: name, birthdate, role. For events: date, location, participants.Group into tables
Create a table for each entity. Each row is one record (a person, an event), and each column is an attribute (date, name, place).Assign primary keys
Each table needs a unique identifier. This could be a number or code that ensures each record can be distinguished from the others.Define relationships
Work out how the tables connect:One-to-one: each person has one passport.
One-to-many: one event may have many participants.
Many-to-many: people may attend many events, and events may involve many people. This often requires a “join table” to manage the link.
Normalise the structure
Avoid redundancy. For example, instead of repeating the same address for multiple people, store the address in its own table and link it.Prototype and test
Build a draft version in software like PostgreSQL, MySQL, or Access. Enter sample data and test queries to ensure it delivers the insights you need.Create forms and documentation
Add user-friendly entry points for data input and document the schema so others can understand and maintain it.Maintain and adapt
A database is never truly finished. As your research or product evolves, you may need to add new tables, fields, or relationships.

takeaways for AI & Data-Driven Innovation
What makes the lessons from Digital Humanities particularly valuable for industry and innovation teams is not only the mindset of interpretation, but also the breadth of methods and tools available to operationalise it. These methods are diverse, ranging from standards and annotation frameworks to computational libraries and visualisation platforms.
Taken together, these methods show that the digital humanities provide a toolkit of interpretive infrastructures: standards, provenance frameworks, encoding practices, visualisation methods, and multimodal workflows. Each directly mitigates a critical risk identified in the AI literature—whether the collapse of meaning into form, the invisibility of bias, or the limited grounding of contextual embeddings. Where AI research often prioritises scale and efficiency, the humanities offer interpretive resilience, ensuring that data remains meaningful, transparent, and situated.
The convergence of AI and digital humanities demonstrates that the future of data-driven innovation depends as much on interpretation as on computation. While technical advances in large language models and generative AI improve scale and efficiency, they do not solve fundamental problems of meaning, provenance, or context. Digital humanities methods provide the interpretive infrastructures that fill these gaps.
The risks identified by Bender and Koller (2020), Rogers (2021), and Smith (2019) are already shaping the reliability and trustworthiness of today’s AI systems. Collapsing meaning into surface patterns, embedding historical biases, and failing to ground outputs in context all lead to brittle and misleading systems. The Oxford Humanities Data Programme sessions show that these challenges can be systematically mitigated through a diverse set of practices:
Standards and Provenance Frameworks ensure that the assumptions embedded in schemas, metadata, and databases remain transparent and accountable.
Corpus Management and FAIR Principles keep data reusable, interpretable, and robust, making biases and choices visible rather than hidden.
Data Cleaning and Relational Modelling (OpenRefine, relational databases, TEI) provide the workflow to move from messy sources to structured, contextualised datasets that both humans and machines can use reliably.
Encoding and Annotation embed interpretive layers into texts and corpora, enriching machine learning inputs with cultural, linguistic, and structural information.
Visualization Frameworks reveal structures and biases in data, acting as interpretive tools that keep computational outputs accountable.
Preservation and Interoperability (IIIF, PDF/A, SIARD) safeguard continuity across technological shifts, ensuring that today’s resources remain usable tomorrow.
Multimodal Approaches extend these principles beyond text to images, audio, and objects, countering the reductionism of text-only AI systems.
What emerges is not a single solution but a diverse ecosystem of methods and tools that treat data as interpretive rather than purely formal. From metadata standards and corpus infrastructures to visualisation frameworks, encoding schemes, and multimodal systems, digital humanities practices directly address the risks of opaque, brittle, and decontextualised AI systems.
Taken together, these methods demonstrate a principle: meaning must be embedded at every stage of the data lifecycle—in standards, cleaning, modelling, encoding, visualisation, and preservation. This interpretive infrastructure does not slow innovation. It accelerates it by creating systems that are transparent, auditable, and trustworthy.
For innovation and R&D teams, the message is clear:
Products built on interpretive infrastructures are more likely to generalize across markets and adapt to regulation.
Research workflows that integrate provenance and FAIR principles produce results that can be reproduced, extended, and trusted.
Data pipelines enriched with encoding, annotation, and visualization are less brittle, more transparent, and better aligned with user expectations.
A Governance Ladder for GenAI and Agentic AI
The roadmap for responsible deployment can be thought of as a ladder from form to action:
Form: Use large models for efficient pattern recognition, but do not mistake fluency for understanding.
Context: Shape behaviour through careful data curation, documentation, and provenance tracking.
Grounding: Connect outputs to structured knowledge, multimodal inputs, or real-world interactions where accuracy matters.
Action: For agentic AI, constrain and monitor execution, ensuring a human remains in the loop.
Each step upward requires stronger oversight and clearer documentation. Businesses that climb responsibly unlock real value. Those that skip steps risk failure at scale.
Think of these provocations as a governance ladder. Each step upward, from form to action, requires stronger oversight, clearer documentation, and tighter alignment with human goals. Businesses that climb responsibly will unlock real value; those that skip steps risk costly failures.
Technologies and standards are not objective. They reflect the priorities of their designers. Preparing material for others to reuse is difficult, but it is the only way to create lasting impact. No single standard or tool will meet every need. Choose deliberately, adapt carefully, and keep interpretation at the centre of your practice.
The humanities remind us that data is cultural before it is computational. Managing it well is less about squeezing performance today, and more about ensuring it can be found, trusted, and reused tomorrow. For industries racing ahead with generative AI and agentic systems, this is the lesson: don’t just build smarter models—build data ecosystems that last.